Experimental Validation of an Artificial Intelligence-Based System for Identifying Optimal Soil Conditions based on Crop Yield
Abstract
Artificial intelligence (AI) has the potential to transform agricultural decision-making by enabling data-driven evaluation of soil conditions that influence crop health and yield. This study investigates whether an AI-based, sensor-driven soil analysis system can accurately identify optimal soil conditions based on crop yield magnitude when compared to random selection. A Random Forest Regression model was trained using publicly available soil and crop yield datasets to predict relative corn yield based on soil parameters. The model achieved a coefficient of determination (R2) corresponding to a 97.22% accuracy. A custom-engineered soil sensing device and commercially available soil testing kits were used to measure soil pH and related parameters for each sample. Soil samples were prepared under low, optimal, and high pH conditions. During physical testing, the AI-based system distinguished the optimal pH condition from the low and high pH samples. These results demonstrate that AI-driven analysis using low-cost sensors and testing tools can reliably predict relative crop yield and identify favorable soil conditions. Future work will incorporate additional experimental variables, such as soil moisture and temperature, both individually and in combination, to assess model performance under more complex and realistic soil environments.
Introduction
Agriculture plays a critical role in sustaining global food security as population growth, climate variability, and resource limitations increasingly strain food production systems worldwide. As economies develop and demand intensifies, agricultural productivity must increase without proportional expansion in arable land or environmental degradation (Zhang & Diao, 2020). Therefore, crop yield optimization remains a central challenge in modern agriculture. Ensuring stable and high crop yields depends not only on genetic improvements but also on environmental and soil-based factors that determine plant health and nutrient availability (Klopp et al., 2025). Among these factors, soil quality has consistently been identified as one of the most significant determinants of crop performance. Soil properties such as pH, nutrient concentration, moisture, and temperature directly influence root development, nutrient uptake, microbial activity, and overall plant growth. Long-term field studies have demonstrated that even modest deviations from optimal soil conditions can result in measurable reductions in crop yield, increased susceptibility to disease, and inefficient fertilizer utilization (Klopp et al., 2025).
Despite the recognized importance of soil quality, traditional soil testing methods remain a barrier for many agricultural producers. Conventional laboratory-based soil analysis often requires specialized equipment such as spectrometers, chromatography systems, and chemical reagents, as well as trained personnel to interpret results. These analyses can be time-consuming, costly, and geographically inaccessible, particularly for farmers operating at small or household scales. As a result, soil testing is frequently performed infrequently or not at all, limiting farmers’ ability to make data-driven management decisions. Small-scale and homestead farms, typically defined as agricultural operations producing primarily for local consumption or limited commercial distribution, often lack access to advanced agronomic services due to financial, logistical, or infrastructural constraints (Zhang & Diao, 2020). This disparity contributes to yield inefficiencies and reinforces inequities in agricultural productivity between large-scale commercial operations and smaller producers.
Recent advances in artificial intelligence (AI) have introduced new opportunities to address these challenges by enabling predictive, data-driven agricultural decision-making. Machine learning techniques have demonstrated strong potential in modeling complex, nonlinear relationships between environmental variables and crop outcomes, allowing for improved yield estimation, disease detection, and resource optimization (Aijaz et al., 2025; Nautiyal et al., 2025). In particular, AI-based regression and deep learning models have been successfully applied to agricultural datasets to predict crop yield based on climatic, soil, and management variables. These approaches offer the advantage of adapting to diverse growing conditions while reducing reliance on extensive manual analysis. Many existing AI-driven agricultural studies, however, rely heavily on remote sensing technologies such as drone imagery, satellite data, and multispectral image analysis. While effective at large spatial scales, these systems often require expensive hardware, specialized imaging platforms, and substantial computational resources for image processing and model training (Lu et al., 2025).
Additionally, image-based approaches may struggle to accurately capture subsurface soil properties such as nutrient concentration or pH, which play a critical role in crop performance. Environmental factors such as cloud cover, lighting variability, and sensor calibration further complicate the reliability of aerial data acquisition. These limitations restrict the accessibility of such technologies for small-scale farmers and highlight the need for alternative AI-integrated solutions that rely on direct, ground-level measurements.
Methods and Materials
Random Forest Regression Model Development
A Random Forest model was used to predict optimal soil conditions using the variables pH, crop-type, moisture, temperature, and nitrogen, phosphorus, and potassium (NPK) concentrations. Random Forest is a supervised machine learning algorithm that can be applied to both classification and regression tasks. The algorithm operates by constructing multiple decision trees or hierarchical structures that map decision pathways through nodes representing variable splits and outcomes. The regression decision trees used in this study predict continuous numerical outcomes based on multiple environmental variables. The Random Forest algorithm aggregates predictions from multiple decision trees and averages them to produce a final predicted value.
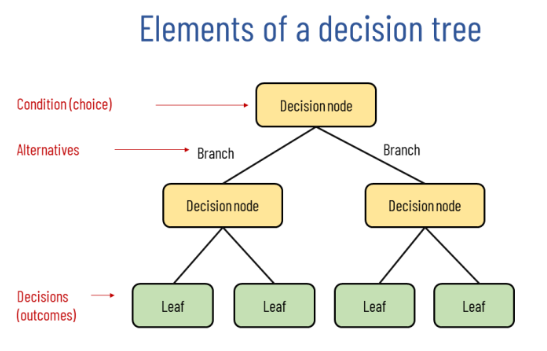
Figure 1. Visualization of a singular Decision Tree with Decision and Leaf Nodes (Kosarenko, 2021)
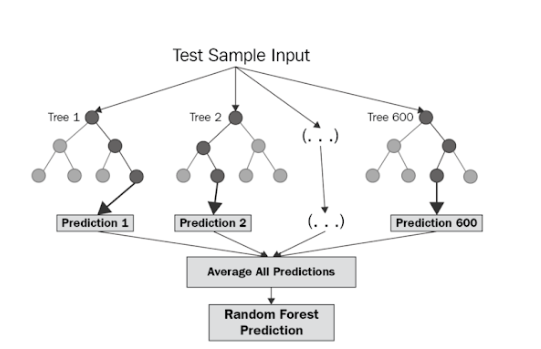
Figure 2. Visualization of Multiple Decision Trees in a Random Forest (Keboola, 2020)
This study selected Random Forest Regression because of its effectiveness in handling nonlinear relationships and continuous outcome variables. The model was trained using a publicly available Kaggle dataset containing the variables of humidity (soil moisture), pH, NPK concentration, crop type, temperature, wind speed, and crop yield measured in tonnes per hectare. Wind speed was removed during preprocessing because the engineering system did not include wind speed measurement capabilities. The data was split into a 70:30 ratio, with 70% used for model training and 30% reserved for testing. During training, the model learned predictive patterns from the training dataset and generated yield predictions based on the relationships among environmental variables.
Engineered Combined Sensor Component
An Arduino R3 microcontroller was used to collect soil sensor data. Sensors were selected to measure soil moisture, temperature, and additional environmental parameters relevant to crop growth. Custom Arduino code was developed to read sensor outputs and transmit data for later input into the AI model. A complete wiring diagram configuration was designed to integrate a capacitive soil moisture sensor, DS18B20 waterproof temperature probe, analog soil pH probe, and analog EC/TDS sensor module. The Arduino system was connected to a computer via USB for data transfer. The system utilized C++ programming to read sensor outputs and process environmental measurements. A portable, waterproof housing for the device was designed using Onshape CAD software.
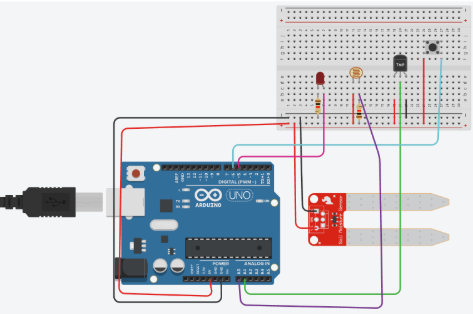
Figure 3. Complete Wiring Diagram for Engineering Component
Figure 4. Onshape CAD Container

Figure 5. Final Assembly
Experimental Design
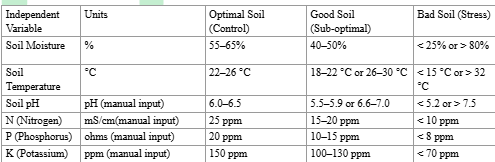
Before data collection, optimal soil conditions for corn growth were identified through an agricultural literature review. Based on these findings, three soil samples representing low, optimal, and high pH conditions were prepared.
Table 1. Independent Variables Table (Corn)
Buffer solutions were used to adjust soil pH levels, and each sample was placed in a separate container. Soil samples were allowed to stabilize for ten minutes before testing to ensure accuracy. Samples from each container were transferred into testing tubes. A validated commercial soil testing kit was used to measure nitrogen, phosphorus, and potassium concentrations for each sample. Temperature and humidity were held constant to isolate the effects of soil chemistry on predicted crop yield.
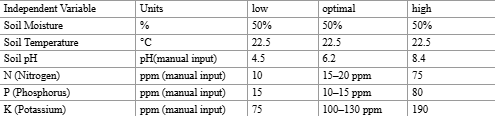
Measured soil values were manually entered into the AI interface. The trained Random Forest Regression model generated predicted crop yield values for each soil condition. All outputs were recorded and analyzed to evaluate how variations in soil chemistry influenced predicted yield outcomes under controlled environmental conditions.
Table 2. Inputted Values into AI Model (Corn)
Results
Statistical Analysis of Random Forest Regression Model
The Random Forest Regression model obtained a Mean Absolute Error (MAE) of 2.501, the average difference between predicted and actual crop yield values within the dataset. This indicates that, on average, the model’s predictions deviated by 2.501 units from observed yield values. The model also achieved a Root Mean Squared Error (RMSE) value of 4.302. RMSE penalizes larger prediction errors more heavily by squaring individual errors before averaging them and then taking the square root. The model obtained a coefficient of determination (R²) value of 0.9722
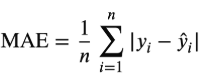
Mean Absolute Error
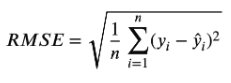
Root Mean Squared Error
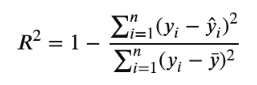
R² Coefficient of Determination
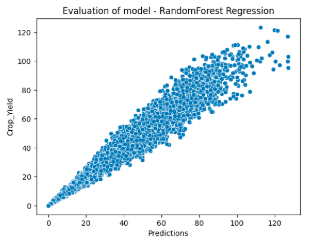
Figure 6. A Visualization of the Strong Linear Relationship of the Model’s Predicted Crop Yield Values and the Actual Values Provided from the Dataset
Testing Phase Results
The Random Forest Regression model correctly identified pH 6.2 as the optimal soil condition for corn growth by predicting the highest crop yield at this pH of 6.2 compared to suboptimal pH values of 4.1 and 8.4, with all other variables held constant.
Discussion
The first result of this study demonstrated that the Random Forest Regression model achieved an R² value of 0.9722 between predicted and observed crop yield data, indicating strong predictive capability. This suggests that the model successfully captured nonlinear interactions among soil variables, supporting its suitability for agricultural regression applications. The model’s strong predictive performance suggests that the input could be expanded to incorporate additional physicochemical soil properties, including soil density, electrical conductivity, and trace mineral composition. Additionally, the model could potentially incorporate anthropogenic soil influences such as mechanical compaction or industrial contamination. However, strong performance on training and validation datasets does not guarantee generalizability across field environments. Soil composition varies significantly across geographic regions and seasonal conditions, emphasizing the need for future validation using diverse field datasets. While an R² value above 0.90 indicates high predictive accuracy, the elevated RMSE and MAE values suggest the potential for mild overfitting, where the model may capture dataset-specific patterns too closely. Further validation using real-world experimental data is necessary to evaluate generalizability.
Table 3. Results from AI Model (Corn)

The second major result demonstrated that the AI-based system assigned the highest predicted yield to the soil sample with optimal pH, aligning with established agronomic thresholds. This confirms the model’s ability to translate numerical inputs into biologically meaningful classifications. However, predicted yield values showed relatively small variation across pH levels, suggesting limited sensitivity to extreme soil conditions. This reduced variance may result from ensemble averaging effects inherent in Random Forest algorithms. Additionally, only selected variables, primarily pH and NPK levels, were varied during testing. Future experiments incorporating simultaneous variation of multiple environmental factors—such as soil moisture and temperature—may produce greater differentiation in predicted yield outcomes. Controlled laboratory testing also limits exposure to natural stressors such as microbial diversity, weather variability, and root competition. Incorporating field-based testing may improve model sensitivity and predictive realism.
Overall, results demonstrate that while the AI system effectively identifies optimal soil conditions, additional environmental complexity and field validation are necessary to strengthen quantitative yield prediction accuracy.
Conclusion
The AI model achieved 97.22% predictive accuracy in modeling yield variation and reliably distinguished between low, optimal, and high pH soil samples. The results demonstrate the effectiveness of the system as a soil evaluation tool. Future development will focus on engineering a fully integrated soil probe capable of electronically measuring core physical and chemical soil state variables governing plant growth. The system could be deployed directly in agricultural fields to continuously monitor environmental conditions and alert farmers to unfavorable soil changes. Unlike conventional soil sensors that rely solely on electrical conductivity to estimate NPK levels, CropMaster integrates sensor data with predictive modeling to generate more comprehensive soil condition assessments. Although CropMaster does not directly measure NPK concentrations electronically, predictive modeling allows for highly accurate estimation when calibrated against traditional testing methods. By combining sensor-based monitoring with machine learning, CropMaster provides accessible soil analysis for small-scale farmers lacking historical environmental datasets. The system enables targeted input application, improves yield efficiency, and reduces waste. With a development cost of approximately $156, the system demonstrates strong accessibility, scalability, and reproducibility, making it a promising tool for modern precision agriculture.
References
Aijaz, N., Lan, H., Raza, T., Yaqub, M., Iqbal, R., & Pathan, M. S. (2025). Artificial intelligence in agriculture: Advancing crop productivity and sustainability. Journal of Agriculture and Food Research, 20, 101762. https://doi.org/10.1016/j.jafr.2025.101762
Keboola. (2020, September 17). The Ultimate Guide to Random Forest Regression. Retrieved February 6, 2026, from www.keboola.com website: https://www.keboola.com/blog/random-forest-regression
Klopp, H. W., Blanco- Canqui, H., Jasa, P., Slater, G., & Ferguson, R. B. (2025). Lessons about soil health and corn yield after a decade of cover crop and corn residue management. Field Crops Research, 326, 109860. https://doi.org/10.1016/j.fcr.2025.109860
Kosarenko, Y. (2021, November 14). How to Create Decision Trees for Business Rules Analysis. Retrieved February 6, 2026, from Why Change website: https://why-change.com/2021/11/13/how-to-create-decision-trees-for-business-rules-analysis/
Lu, J., Li, J., Fu, H., Zou, W., Kang, J., Yu, H., & Lin, X. (2025). Estimation of rice yield using multi-source remote sensing data combined with crop growth model and deep learning algorithm. Agricultural and Forest Meteorology, 370, 110600. https://doi.org/10.1016/j.agrformet.2025.110600
Nautiyal, M., Joshi, S., Hussain, I., Rawat, H., Joshi, A., Saini, A., Kapoor, R., Verma, H., Nautiyal, A., Chikara, A., Ahmad, W., & Kumar, S. (2025). Revolutionizing agriculture: A comprehensive review on artificial intelligence applications in enhancing properties of agricultural produce. Food Chemistry: X, 29, 102748. https://doi.org/10.1016/j.fochx.2025.102748
Zhang, Y., & Diao, X. (2020). The changing role of agriculture with economic structural change – The case of China. China Economic Review, 62, 101504. https://doi.org/10.1016/j.chieco.2020.101504